文章目录
- week46 FMP
- 摘要
- Abstract
- 1. 题目
- 2. Abstract
- 3. FMP
- 3.1 优化框架
- 3.2 优化器
- 4. 文献解读
- 4.1 Introduction
- 4.2 创新点
- 4.3 实验过程
- 5. 结论
- 6.代码复现
- 1. FMP
- 2. fairGNN
- 小结
- 参考文献
week46 FMP
摘要
本周阅读了题为Chasing Fairness in Graphs: A GNN Architecture Perspective的论文。该文提出了一种基于图神经网络(GNN)统一优化框架指导的公平消息传递方案(FMP),旨在提高图数据处理的公平性。该方案通过两个核心步骤实现:首先聚合图数据,随后明确追求代表各统计学群体中心以减少偏见。该方法构建了一个同时考虑公平性和数据平滑性的优化问题,并运用Fenchel共轭和梯度下降技术结合softmax函数特性来高效求解,生成既公平又信息丰富的节点表示。此方案直接嵌入到GNN中,以改善节点分类任务的公平性和准确性,无需数据预处理。实验结果显示,在真实数据集上,FMP较多个基线模型表现更佳,从模型架构、效率及敏感属性利用等角度全面验证了其有效性。
Abstract
This week’s weekly newspaper decodes the paper entitled Chasing Fairness in Graphs: A GNN Architecture Perspective. This paper introduces a Fair Message Passing (FMP) scheme guided by a unified optimization framework of Graph Neural Networks (GNNs), aiming to enhance fairness in graph data processing. The FMP achieves this through two core steps: first, aggregating graph data, and then explicitly striving to represent the centers of various statistical groups to mitigate bias. This approach formulates an optimization problem that considers both fairness and data smoothness, and leverages Fenchel duality and gradient descent techniques, combined with the properties of the softmax function, to efficiently solve the problem and generate fair and informative node representations. This scheme is directly embedded into GNNs to improve the fairness and accuracy of node classification tasks, without the need for data preprocessing. Experimental results on real-world datasets show that FMP outperforms multiple baseline models, comprehensively validating its effectiveness from the perspectives of model architecture, efficiency, and the utilization of sensitive attributes.
1. 题目
标题:Chasing Fairness in Graphs: A GNN Architecture Perspective
作者:Zhimeng Jiang1, Xiaotian Han1, Chao Fan2, Zirui Liu3, Na Zou4, Ali Mostafavi1, Xia Hu3
发布:Vol. 38 No. 19: AAAI-24
链接:https://doi.org/10.1609/aaai.v38i19.30115
2. Abstract
该文旨在通过新的 GNN 框架实现更好的公平性,故提出在 GNN 的统一优化框架内设计的公平消息传递(FMP)。值得注意的是,FMP 使用交叉熵损失显式地呈现节点分类任务的前向传播中敏感属性的使用,而无需进行数据预处理。在FMP中,首先采用聚合来利用邻居的信息,然后偏差缓解步骤明确地将数据统计组节点表示中心推到一起。通过这种方式,FMP 方案可以聚合来自邻居的有用信息并减轻偏差,以实现更好的公平性和预测权衡性能。节点分类任务的实验表明,所提出的 FMP 在三个真实世界数据集上的公平性和准确性方面优于多个基线。
3. FMP
FMP 可以从模型主干的角度实现公平的预测。具体来说,将公平消息传递制定为一个优化问题,以同时追求平滑性和公平节点表示。结合有效且高效的优化算法,推导出封闭形式的公平消息传递。最后,所提出的 FMP 在三个阶段被集成到公平的 GNN 中,包括变换、聚合和去偏差步骤,如图 1 所示。这三个阶段分别采用节点特征、图拓扑和敏感属性。
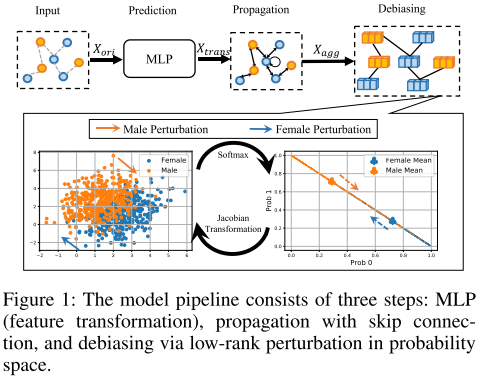
3.1 优化框架
min F λ s 2 t r ( F T T ~ F ) + 1 2 ∣ ∣ F − X t r a n s ∣ ∣ F 2 + λ f ∣ ∣ Δ s S F ( F ) ∣ ∣ 1 (1) \min_{\mathbf F}\frac{\lambda_s}{2}tr(\mathbf F^T \tilde {\mathbf T}\mathbf F)+\frac12||\mathbf F-\mathbf X_{trans}||^2_F+\lambda_f||\Delta_sSF(\mathbf F)||_1 \tag{1} Fmin2λstr(FTT~F)+21∣∣F−Xtrans∣∣F2+λf∣∣ΔsSF(F)∣∣1(1)
$\tilde L 表示归一化拉普拉斯矩阵, 表示归一化拉普拉斯矩阵, 表示归一化拉普拉斯矩阵,h_s(·)$ 和 h f ( ⋅ ) h_f(·) hf(⋅) 表示平滑性和公平性目标, X t r a n s ∈ R n × d o u t X_{trans} \in R^{n×d_{out}} Xtrans∈Rn×dout 是变换后的 d o u t d_{out} dout维节点特征。 F ∈ R n × d o u t F \in R^{n×d_{out}} F∈Rn×dout 是相同矩阵大小的聚合节点特征。
前两项保留了连接节点表示的相似性,从而增强了图的平滑性。最后一项强制执行公平的节点表示,以便不同敏感属性组之间的平均预测概率可以保持不变。
正则化系数 λs 和 λf 自适应地控制图平滑性和公平性之间的权衡。
h
s
(
F
)
=
min
F
λ
s
2
t
r
(
F
T
T
~
F
)
+
1
2
∣
∣
F
−
X
t
r
a
n
s
∣
∣
F
2
h_s(\mathbf F)=\min_{\mathbf F}\frac{\lambda_s}{2}tr(\mathbf F^T \tilde {\mathbf T}\mathbf F)+\frac12||\mathbf F-\mathbf X_{trans}||^2_F
hs(F)=Fmin2λstr(FTT~F)+21∣∣F−Xtrans∣∣F2
平滑度目标 hs(·):现有图消息传递方案中的相邻矩阵被归一化,以提高数值稳定性并实现卓越的性能。从以边为中心的角度来看,平滑目标强制连接的节点表示相似,因为
t
r
(
F
T
T
~
F
)
=
∑
(
v
i
,
v
j
)
∈
E
∣
∣
F
i
d
i
+
1
−
F
i
d
j
+
1
∣
∣
F
2
(2)
tr(\mathbf F^T \tilde {\mathbf T}\mathbf F)=\sum_{(v_i,v_j)\in {\Epsilon}}||\frac{\mathbf F_i}{\sqrt {d_i+1}}-\frac{\mathbf F_i}{\sqrt{d_j+1}}||^2_F \tag{2}
tr(FTT~F)=(vi,vj)∈E∑∣∣di+1Fi−dj+1Fi∣∣F2(2)
公平目标 hf(·):公平性目标衡量聚合后节点表示的偏差。敏感属性事件向量 Δs 通过符号和绝对值求和表示敏感属性组和组大小。敏感属性事件向量为
Δ
s
=
1
>
0
(
s
)
∣
∣
1
>
0
(
s
)
∣
∣
1
−
1
>
0
(
−
s
)
∣
∣
1
>
0
(
−
s
)
∣
∣
1
(3)
\Delta_s=\frac{\mathbf 1_{>0}(\mathbf s)}{||\mathbf 1_{>0}(\mathbf s)||_1}-\frac{\mathbf 1_{>0}(-\mathbf s)}{||\mathbf 1_{>0}(-\mathbf s)||_1} \tag{3}
Δs=∣∣1>0(s)∣∣11>0(s)−∣∣1>0(−s)∣∣11>0(−s)(3)
SF(F) 表示节点分类任务的预测概率,其中
S
F
(
F
)
i
j
=
P
^
(
y
i
=
j
∣
X
)
SF(\mathbf F)_{ij} = \hat P(y_i = j|\mathbf X)
SF(F)ij=P^(yi=j∣X)。公平性目标,
Δ
s
S
F
(
F
)
Δ_sSF(F)
ΔsSF(F) 的 l1 范数表征了具有不同敏感属性的两组之间的预测概率差异。因此,提出的优化框架可以同时追求图的平滑性和公平性。
(
Δ
s
S
F
(
F
)
)
j
=
P
^
(
y
i
=
j
∣
s
i
=
1
,
X
)
−
P
^
(
y
i
=
j
∣
s
i
=
−
1
,
X
)
(Δ_sSF(F))_j=\hat P(y_i=j|s_i=1,\mathbf X)-\hat P(y_i=j|\mathbf s_i=-1,\mathbf X)
(ΔsSF(F))j=P^(yi=j∣si=1,X)−P^(yi=j∣si=−1,X)
3.2 优化器
双级优化问题公式化:Fenchel 共轭(又名凸共轭)(Rockafellar 2015)可以使用原始算法将原始问题转换为等效鞍点问题(Liu et al. 2021)。这样可以降低计算复杂度并兼容反向传播训练。类似地,为了以更有效和高效的方式解决优化问题1,引入Fenchel共轭(Rockafellar 2015)将原始问题转化为双层优化问题。对于一般凸函数h(·),其共轭函数定义为
h
∗
(
U
)
≜
s
u
p
X
⟨
U
,
X
⟩
−
h
(
X
)
h^*(U) \triangleq sup_X ⟨U,X⟩ − h(X)
h∗(U)≜supX⟨U,X⟩−h(X)。基于 Fenchel 共轭,公平性目标可以转化为变分表示
h
f
(
p
)
=
s
u
p
u
⟨
p
,
u
⟩
−
h
f
∗
(
u
)
h_f(p) = sup_u ⟨p, u⟩ − h^∗_f(u)
hf(p)=supu⟨p,u⟩−hf∗(u),其中
p
=
Δ
s
S
F
(
F
)
∈
R
1
×
d
o
u
t
p = Δ_sSF(F) ∈ R^{1×d_{out}}
p=ΔsSF(F)∈R1×dout 是预测概率用于分类的向量。此外,原始优化问题等价于
min
F
max
u
h
s
(
F
)
+
⟨
p
,
u
⟩
+
h
f
∗
(
u
)
(4)
\min_{\mathbf F}\max_{\mathbf u}h_s(\mathbf F)+⟨p,u⟩+h^*_f(u) \tag{4}
Fminumaxhs(F)+⟨p,u⟩+hf∗(u)(4)
解决方法:最小-最大优化问题 (4) 可以通过以下定点方程求解,每次迭代计算复杂度较低和收敛保证
{
F
=
F
−
∇
h
s
(
F
)
−
∂
⟨
p
,
u
⟩
∂
F
u
=
prox
h
f
∗
(
u
+
Δ
s
S
F
(
F
)
)
(5)
\begin{cases} \mathbf F=\mathbf F-\nabla h_s(\mathbf F)-\frac{\partial ⟨p,u⟩}{\partial \mathbf F}\\ \mathbf u=\text{prox}_{h^*_f}(\mathbf u+\Delta_s SF(\mathbf F)) \end{cases} \tag{5}
{F=F−∇hs(F)−∂F∂⟨p,u⟩u=proxhf∗(u+ΔsSF(F))(5)
采用迭代算法来寻找最小-最大优化问题的鞍点。具体来说,从 (Fk, uk) 开始,对原始变量 F 采用梯度下降步骤到达
(
F
‾
k
+
1
,
u
k
)
( \overline {\mathbf F}^{k+1}, \mathbf u^k)
(Fk+1,uk),然后在对偶变量 u 中进行近端上升步骤。最后,对点
(
F
‾
k
+
1
,
u
k
)
(\overline {\mathbf F}^{k+1}, \mathbf u^k)
(Fk+1,uk) 中的原始变量进行梯度下降以到达
(
F
k
+
1
,
u
k
)
(\mathbf F^{k+1}, \mathbf u^k)
(Fk+1,uk)。简而言之,迭代可以概括为:
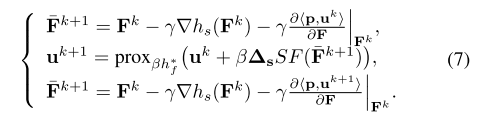
其中 γ 和 β 是原始变量和对偶变量的步长。注意, ∂ ⟨ p , u ⟩ ∂ F ∈ R n × d o u t \frac{\partial ⟨p,u⟩}{ \partial F} ∈ R^{n×d_{out}} ∂F∂⟨p,u⟩∈Rn×dout 和 prox β h f ∗ ( ⋅ ) \text{prox}_{βh^∗_f} (·) proxβhf∗(⋅) 的闭式还不清楚,将提供解决方案。
FMP:令 γ = 1 1 + λ s , β = 1 2 γ \gamma=\frac1{1+\lambda_s},\beta=\frac1{2\gamma} γ=1+λs1,β=2γ1有
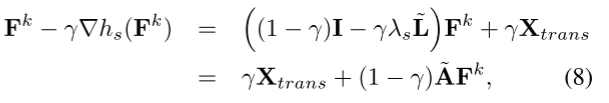
故可将提出的 FMP 总结为两个阶段,包括跳跃连接传播 step1 和偏差缓解 step2-5。step2更新聚合节点特征以实现公平性目标;step3&4旨在分别学习和“重塑”概率空间中的扰动向量。step5基于原始变量的梯度下降显式减轻节点特征的偏差。数学公式如下:
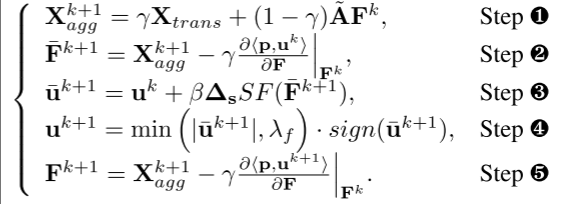
梯度计算加速:采用softmax属性来加速梯度计算。
根据下面定理中的softmax函数的性质简化了梯度计算。
T
h
e
o
r
e
m
0.2
(
Gradient Computation
)
\mathbf {Theorem\ 0.2}(\text{Gradient\ Computation})
Theorem 0.2(Gradient Computation)
T
h
e
g
r
a
d
i
e
n
t
o
v
e
r
p
r
i
m
a
l
v
a
r
i
a
b
l
e
∂
⟨
p
,
u
⟩
∂
F
s
a
t
i
s
f
i
e
s
\\The\ gradient\ over primal\ variable\ \frac{\partial ⟨p,u⟩}{\partial \mathbf {F}}\ satisfies\\
The gradient overprimal variable ∂F∂⟨p,u⟩ satisfies
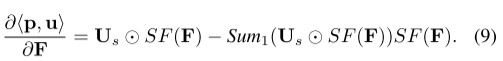
这样的梯度计算可以解释为三个步骤:Softmax变换、概率空间中的扰动以及表示空间中的去偏。具体来说,首先通过 softmax 变换将节点表示映射到概率空间。随后,计算概率空间中公平目标的梯度。可以看出,扰动 Δ s ⊤ u Δ^⊤_s u Δs⊤u 实际上在概率空间中造成了低秩去偏,其中具有不同敏感属性的节点包含相反的扰动。换句话说,对偶变量u代表概率空间中的扰动方向。最后,概率空间中的扰动将通过雅可比变换 ∂ S F ( F ) ∂ F \frac{∂SF(F)}{∂F} ∂F∂SF(F)变换到表示空间。
FMP可以为敏感属性提供白盒形式的调用,因为可以直接识别出敏感属性的使用是在前向传播期间强制统计学上的组节点表示中心聚集在一起。
4. 文献解读
4.1 Introduction
该文通过设计一个由 GNN 的统一优化框架指导的公平消息传递方案来提供确定性。
实现公平消息传递的关键思想是
- 首先聚合,
- 然后通过明确追求一致的人口群体代表中心来减轻偏见。
具体来说,
- 首先制定一个集成图数据的公平性和平滑性目标的优化问题。
- 然后,通过 Fenchel 共轭和梯度下降来解决公式化的问题,以生成公平且信息丰富的表示,其中采用 softmax 函数的特性来加速原始变量的梯度计算。
- 此外,将优化问题求解器解释为两个主要步骤。
- 最后,将FMP集成到图神经网络中,以实现节点分类任务的公平和准确的预测。
4.2 创新点
该文的主要贡献有四个方面:
- 证明了精心设计的 GNN 架构可以提高图数据的公平性的概念验证。与专注于数据预处理和公平训练策略设计的传统方法相比,工作提供了全新的前景。
- 提出FMP,在统一优化框架的指导下,通过在消息传递中明确纳入敏感属性信息来实现公平性。此外,引入了一种基于softmax属性的加速方法来降低梯度计算复杂度。
- FMP 的有效性和效率在三个真实数据集上进行了实验评估。结果表明,与最先进的技术相比,FMP 在预测性能和公平性之间表现出相当或更好的权衡,而计算开销可以忽略不计。
4.3 实验过程
数据集:Pokecz 和 Pokec-n 是根据省份信息从斯洛伐克一个更大的类 Facebook 社交网络 Pokec(Takac 和 Zabovsky 2012)中采样的,其中区域信息被视为敏感属性,预测标签是该网络的工作领域。用户。 NBA 数据集扩展自 Kaggle 数据集 7,其中包含约 400 名 NBA 篮球运动员。球员信息包括年龄、国籍、2016-2017赛季工资等。玩家的链接关系来自Twitter,官方抓取API。采用二元国籍(美国和海外球员)作为敏感属性,预测标签是工资是否高于中位数。
评估标准: Δ D P = ∣ P ( y ^ = 1 ∣ s = − 1 ) − P ( y ^ = 1 ∣ s = 1 ) Δ_{DP} = |P(\hat y = 1|s = −1)−P(\hat y = 1|s = 1) ΔDP=∣P(y^=1∣s=−1)−P(y^=1∣s=1), Δ E O = ∣ P ( y ^ = 1 ∣ s = − 1 , y = 1 ) − P ( y ^ = 1 ∣ s = 1 , y = 1 ) ∣ Δ_{EO} = |P(\hat y = 1|s = −1, y = 1) − P(\hat y = 1|s = 1, y = 1)| ΔEO=∣P(y^=1∣s=−1,y=1)−P(y^=1∣s=1,y=1)∣
基线:将 FMP 与代表性的 GNN 进行比较,GCN、GAT、SGC、APPNP、JKNet和MLP。对于所有模型,训练 2 层具有 64 个隐藏单元的神经网络 300 个时期。此外,还比较了对抗性去偏差和添加统计学正则化方法,以显示所提出方法的有效性。
实施细节:运行实验 5 次并报告每种方法的平均性能。对所有模型采用 Adam 优化器,学习率为 0.001,权重衰减为 10−5。对于对抗性去偏差,采用训练分类器和对手分别具有 70 和 30 epoch。对手损失的超参数在 {0.0, 1.0, 2.0, 5.0, 8.0, 10.0, 20.0, 30.0} 中调整。为了添加正则化,采用超参数集 {0.0, 1.0, 2.0, 5.0, 8.0, 10.0, 20.0, 50.0, 80.0, 100.0}。
与现有 GNN 的比较:表 1 显示了针对 Pokec-z、Pokec-n、NBA 数据集提出的 FMP 与 MLP、GAT、GCN、SGC 和 APPNP 的准确性、人口统计平等性和平等机会指标。这三个数据集的详细统计信息如表3所示。
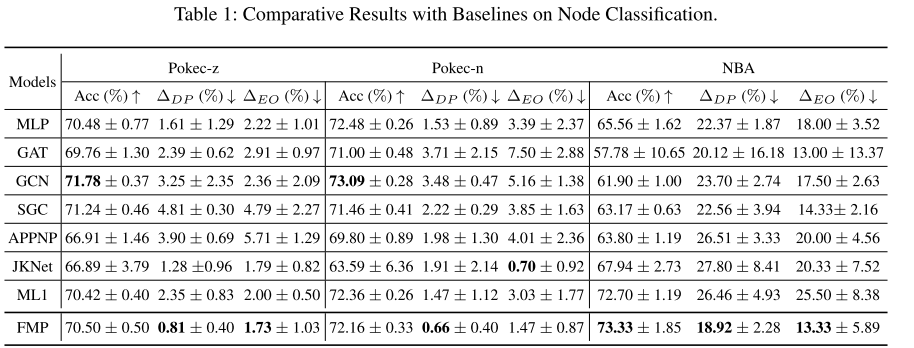
从这些结果中,可以得到以下观察结果:
- 就公平性指标而言,许多现有的 GNN 在所有三个数据集上的 MLP 模型都表现不佳。例如,在 Pokec-z 数据集上,MLP 的人口统计奇偶性比 GAT、GCN、SGC 和 APPNP 低 32.64%、50.46%、66.53% 和 58.72%。较高的预测偏差来自于相同敏感属性节点内的聚合和图数据中的拓扑偏差。
- FMP 在所有数据集的人口平等和机会均等方面始终实现最低的预测偏差。具体而言,与 Pokecz、Pokec-n 和 NBA 数据集中所有基线中的最低偏差相比,FMP 将人口统计均等性降低了 49.69%、56.86% 和 5.97%。同时,FMP 在 NBA 数据集中实现了最佳精度,在 Pokec-z 和 Pokec-n 数据集中达到了相当的精度。简而言之,所提出的 FMP 可以有效减轻预测偏差,同时保持预测性能。
与对抗性去偏和正则化的比较:随机划分 50%/25%/25% 用于训练、验证和测试数据集。图 2 显示了所有方法的帕累托最优曲线,其中右下角点代表理想性能(最高准确度和最低预测偏差)。
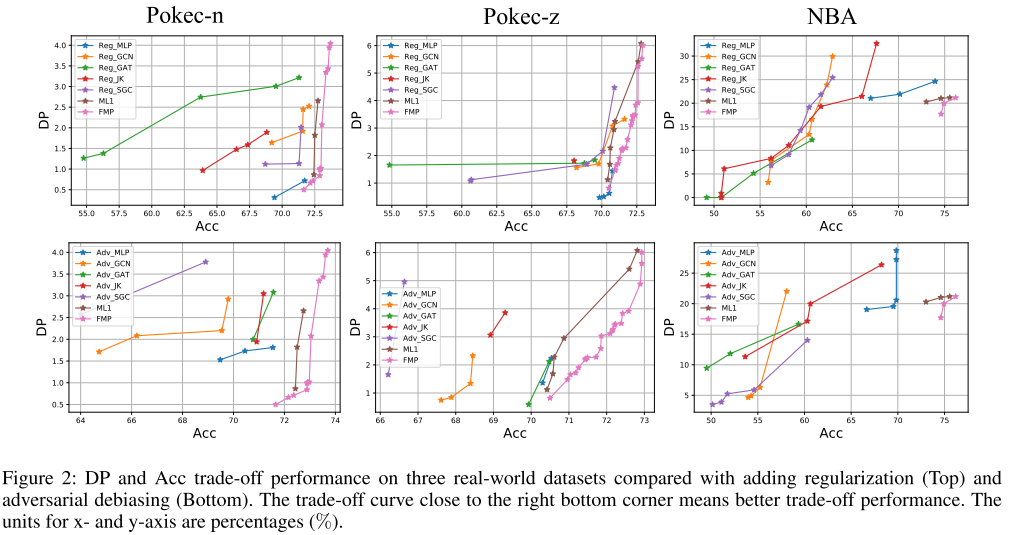
根据结果,列出以下观察结果:
- 与对抗性去偏并为许多 GNN 和 MLP 添加正则化相比,我们提出的 FMP 可以实现更好的 DP-Acc 权衡。这样的观察验证了 FMP 中关键思想的有效性:先聚合,然后去偏。此外,由于透明且高效的去偏差,FMP 可以以可忽略不计的性能成本来降低人口统计平等。
- GNN 中的消息传递确实很重要。为了添加正则化或对抗性去偏差,不同的 GNN 存在巨大差异,这意味着适当的消息传递方式可能会带来更好的权衡性能。此外,许多 GNN 在低标签同质系数数据集(例如 NBA)中表现不如 MLP。基本原理是,当邻居具有相同标签的概率较低时,聚合可能并不总是能带来准确性方面的好处。
5. 结论
在这项工作中,从模型架构的角度提高了图的公平性。设计了一种公平的消息传递方案,以使用普通训练损失来实现节点分类的公平预测,而无需进行数据预处理。具体来说,受 GNN 统一优化框架的推动,FMP 被设计为首先聚合,然后减轻偏差,以明确追求平滑性和公平性目标。还从模型架构解释、效率以及敏感属性的白盒使用方面对FMP进行了全面的讨论。真实数据集上的实验结果证明了 FMP 与节点分类任务中的多个基线相比的有效性。
6.代码复现
tip:该部分代码需要使用numpy1.x
1. FMP
from typing import Optional, Tuple
from torch_geometric.typing import Adj, OptTensor
import torch
from torch import Tensor
import torch.nn.functional as F
import torch.nn as nn
from torch_geometric.nn.conv import MessagePassing
from torch_geometric.nn.conv.gcn_conv import gcn_norm
from dgl.nn.pytorch import GraphConv
import torch_sparse
from torch_sparse import SparseTensor, matmul
def get_sen(sens, idx_sens_train):
sens_zeros = torch.zeros_like(sens)
# print(f'sens={sens}')
sens_1 = sens
sens_0 = (1 - sens)
# print(f'idx_sens_train={idx_sens_train.shape}')
# print(f'idx_sens_train={idx_sens_train.shape}')
# print(f'sens_1={sens_1.shape}')
sens_1[idx_sens_train] = sens_1[idx_sens_train] / len(sens_1[idx_sens_train])
sens_0[idx_sens_train] = sens_0[idx_sens_train] / len(sens_0[idx_sens_train])
# print(f'sens_1={sens_1.shape}')
sens_zeros[idx_sens_train] = sens_1[idx_sens_train] - sens_0[idx_sens_train]
sen_mat = torch.unsqueeze(sens_zeros, dim=0)
# print(f'sen_mat={sen_mat[0, 0:10]}')
# print(f'sen_mat={sen_mat[0, 10:20]}')
return sen_mat
# def sen_norm(sen, edge_index):
# ## edge_index: unnormalized adjacent matrix
# ## normalize the sensitive matrix
# edge_index = torch_sparse.fill_diag(edge_index, 1.0) ## add self loop to avoid 0 degree node
# deg = torch_sparse.sum(edge_index, dim=1)
# deg_inv_sqrt = deg.pow(-0.5)
# sen = torch_sparse.mul(sen, deg_inv_sqrt.view(1, -1)) ## col-wise
# return sen
def check_sen(edge_index, sen):
nnz = edge_index.nnz()
deg = torch.eye(edge_index.sizes()[0]).cuda()
adj = edge_index.to_dense()
lap = (sen.t() @ sen).to_dense()
lap2 = deg - adj
diff = torch.sum(torch.abs(lap2-lap)) / nnz
assert diff < 0.000001, f'error: {diff} need to make sure L=B^TB'
class FMP(GraphConv):
_cached_sen = Optional[SparseTensor]
def __init__(self,
in_feats: int,
out_feats: int,
K: int,
lambda1: float = None,
lambda2: float = None,
L2: bool = True,
dropout: float = 0.,
cached: bool = False,
**kwargs):
super(FMP, self).__init__(in_feats, out_feats)
self.K = K
self.lambda1 = lambda1
self.lambda2 = lambda2
self.L2 = L2
self.dropout = dropout
self.cached = cached
self._cached_sen = None
self.propa = GraphConv(in_feats, in_feats, weight=False, bias=False, activation=None)
def reset_parameters(self):
self._cached_sen = None
def forward(self, x: Tensor,
g,
idx_sens_train,
edge_weight: OptTensor = None,
sens=None) -> Tensor:
"""
前向传播函数
Args:
x (Tensor): 节点特征矩阵
g: 图结构信息
idx_sens_train (Tensor): 训练集中敏感属性的索引
edge_weight (OptTensor, optional): 边权重,默认为None
sens (Tensor, optional): 敏感属性矩阵,默认为None
Returns:
Tensor: 处理后的节点特征矩阵
"""
if self.K <= 0:
return x # 如果传播次数为0或负数,则直接返回输入
cache = self._cached_sen
if cache is None:
# 如果未缓存敏感矩阵,则计算并可能缓存
sen_mat = get_sen(sens=sens, idx_sens_train=idx_sens_train)
if self.cached:
self._cached_sen = sen_mat
# 初始化z,可能用于后续计算
self.init_z = torch.zeros((sen_mat.size(0), x.size(-1))).cuda()
else:
sen_mat = self._cached_sen
# 开始传播和敏感性处理
hh = x # 初始化hh为x
x = self.emp_forward(g, x=x, hh=hh, K=self.K, sen=sen_mat)
return x
def emp_forward(self, g, x, hh, K, sen):
# 获取类的属性lambda1和lambda2,这些可能是正则化项的系数
lambda1 = self.lambda1
lambda2 = self.lambda2
# 计算gamma和beta,这些参数用于后续的加权和正则化
gamma = 1 / (1 + lambda2)
beta = 1 / (2 * gamma)
# 循环K次,可能是执行K步迭代或更新
for _ in range(K):
# 根据lambda2的值决定是否使用自定义传播函数(propa)还是直接使用x
if lambda2 > 0:
y = gamma * hh + (1-gamma) * self.propa(g, feat=x)
else:
y = gamma * hh + (1-gamma) * x
# 如果lambda1 > 0,执行更复杂的更新逻辑
if lambda1 > 0:
# 使用softmax和sen矩阵计算z
z = sen @ F.softmax(y, dim=1) / (gamma * sen @ sen.t())
# 通过z反推出x_bar0,再对x_bar0进行softmax得到x_bar1
x_bar0 = sen.t() @ z
x_bar1 = F.softmax(x_bar0, dim=1)
# 计算修正项correct,用于调整x_bar
correct = x_bar0 * x_bar1
coeff = torch.sum(x_bar0 * x_bar1, 1, keepdim=True)
correct = correct - coeff * x_bar1
x_bar = y - gamma * correct
# 更新z并考虑正则化
z_bar = z + beta * (sen @ F.softmax(x_bar, dim=1))
if self.L2:
# 如果使用L2正则化,则调用L2_projection进行投影
z = self.L2_projection(z_bar, lambda_=lambda1, beta=beta)
else:
# 否则,使用L1正则化
z = self.L1_projection(z_bar, lambda_=lambda1)
# 重新计算x_bar0, x_bar1, correct以考虑正则化后的z
x_bar0 = sen.t() @ z
x_bar1 = F.softmax(x_bar0, dim=1)
correct = x_bar0 * x_bar1
coeff = torch.sum(x_bar0 * x_bar1, 1, keepdim=True)
correct = correct - coeff * x_bar1
# 更新x
x = y - gamma * correct
else:
# 如果lambda1 <= 0,则不执行复杂的更新逻辑,直接令x=y
x = y
# 对x应用dropout,以减少过拟合
x = F.dropout(x, p=self.dropout, training=self.training)
# 返回更新后的x
return x
def L1_projection(self, x: torch.Tensor, lambda_):
"""
对输入张量x应用L1投影。
通过clamp函数将x的值限制在[-lambda_, lambda_]之间。
参数:
x (torch.Tensor): 输入张量。
lambda_ (float): L1投影的限制值。
返回:
torch.Tensor: 应用L1投影后的张量。
"""
return torch.clamp(x, min=-lambda_, max=lambda_)
def L2_projection(self, x: torch.Tensor, lambda_, beta):
"""
对输入张量x应用L2投影,通过缩放x来实现。
参数:
x (torch.Tensor): 输入张量。
lambda_ (float): L2正则化的系数。
beta (float): 另一个系数,可能与正则化强度有关。
返回:
torch.Tensor: 应用L2投影后的张量。
"""
coeff = (2*lambda_) / (2*lambda_ + beta)
return coeff * x
def message(self, x_j: torch.Tensor, edge_weight: torch.Tensor) -> torch.Tensor:
"""
根据边权重计算消息。
将节点特征x_j与边权重相乘,用于图神经网络中的消息传递步骤。
参数:
x_j (torch.Tensor): 目标节点的特征。
edge_weight (torch.Tensor): 边权重。
返回:
torch.Tensor: 乘以边权重后的节点特征,作为消息。
"""
return edge_weight.view(-1, 1) * x_j
def message_and_aggregate(self, adj_t: SparseTensor, x: torch.Tensor) -> torch.Tensor:
"""
在图上进行消息传递和聚合。
使用稀疏矩阵乘法将邻接矩阵adj_t与节点特征x相乘,并根据聚合方式聚合消息。
参数:
adj_t (SparseTensor): 图的邻接矩阵的稀疏表示。
x (torch.Tensor): 节点特征张量。
返回:
torch.Tensor: 聚合后的节点特征张量。
"""
return matmul(adj_t, x, reduce=self.aggr)
def __repr__(self):
"""
返回类的字符串表示,包括类的名称和关键属性。
返回:
str: 类的字符串表示。
"""
return '{}(K={}, lambda1={}, lambda2={}, L2={})'.format(
self.__class__.__name__, self.K, self.lambda1, self.lambda2, self.L2)
2. fairGNN
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Linear
from fmp import FMP
class FairGNN(nn.Module):
"""
FairGNN类,一个结合了公平性约束的图神经网络模型。
Args:
input_size (int): 输入特征的维度。
size (int): 隐藏层的维度。
num_classes (int): 输出的类别数。
num_layer (int): 图神经网络中隐藏层的数量(不包括输入和输出层)。
prop (nn.Module): 自定义的传播层,用于实现公平性相关的图传播逻辑。
**kwargs: 其他可能传递给父类的关键字参数。
"""
def __init__(self, input_size, size, num_classes, num_layer, prop, **kwargs):
super(FairGNN, self).__init__()
# 初始化隐藏层列表
self.hidden = nn.ModuleList()
for _ in range(num_layer-2): # 减去2是因为已经手动添加了输入层和输出层
self.hidden.append(nn.Linear(size, size))
# 输入层
self.first = nn.Linear(input_size, size)
# 输出层
self.last = nn.Linear(size, num_classes)
# 自定义的传播层
self.prop = prop
def reset_parameters(self):
"""
重置模型参数。注意:原始代码中的lin1和lin2在FairGNN类中未定义,这里假设重置所有层。
"""
self.first.reset_parameters()
for layer in self.hidden:
layer.reset_parameters()
self.last.reset_parameters()
# 如果prop层有reset_parameters方法,则也应该调用
if hasattr(self.prop, 'reset_parameters'):
self.prop.reset_parameters()
def forward(self, features, g, sens, idx_sens_train):
"""
前向传播函数。
Args:
features (Tensor): 节点特征矩阵。
g (Graph): 图结构,可能包含边索引和其他图信息。
sens (Tensor): 敏感属性矩阵。
idx_sens_train (Tensor): 训练集敏感属性的索引。
Returns:
Tensor: 模型输出的类别预测。
"""
x = features
# 通过第一层
out = F.relu(self.first(x))
# 通过隐藏层
for layer in self.hidden:
out = F.relu(layer(out))
# 通过输出层
x = self.last(out)
# 应用自定义的传播层,考虑公平性
x = self.prop(x, sens=sens, g=g, idx_sens_train=idx_sens_train)
# 返回原始输出,如果需要,可以在外部调用F.log_softmax
return x
def get_model(args, data):
"""
根据给定的参数和数据构建FairGNN模型。
Args:
args (Namespace): 包含模型配置参数的命名空间。
data (Data): 包含图数据和特征等的数据对象。
Returns:
nn.Module: 构建的FairGNN模型。
"""
Model = FairGNN
# 创建自定义传播层FMP
prop = FMP(in_feats=data.num_features,
out_feats=data.num_features, # 注意:这里out_feats通常为隐藏层大小,这里可能是一个示例
K=args.num_layers, # 注意:这里的K可能与FairGNN中的num_layer不一致,取决于FMP的实现
lambda1=args.lambda1,
lambda2=args.lambda2,
L2=args.L2,
cached=True)
# 构建FairGNN模型
model = Model(input_size=data.num_features,
size=args.num_hidden,
num_classes=data.num_classes,
num_layer=args.num_gnn_layer,
prop=prop).cuda()
return model
小结
该文提出了一种基于图神经网络(GNN)统一优化框架指导的公平消息传递方案(FMP),旨在提高图数据处理的公平性。该方案通过两个核心步骤实现:首先聚合图数据,随后明确追求代表各统计学群体中心以减少偏见。该方法构建了一个同时考虑公平性和数据平滑性的优化问题,并运用Fenchel共轭和梯度下降技术结合softmax函数特性来高效求解,生成既公平又信息丰富的节点表示。此方案直接嵌入到GNN中,以改善节点分类任务的公平性和准确性,无需数据预处理。实验结果显示,在真实数据集上,FMP较多个基线模型表现更佳,从模型架构、效率及敏感属性利用等角度全面验证了其有效性。
未来的阅读计划:
- Hypergraph-enhanced Dual Semi-supervised Graph Classification:ICML2024,HEAL:用于半监督图分类的超图增强对偶框架
- PGODE: Towards High-quality System Dynamics Modeling:ICML2024,PGODE:迈向高质量的系统动力学建模
参考文献
[1] Jiang, Z., Han, X., Fan, C., Liu, Z., Zou, N., Mostafavi, A., & Hu, X. (2024). Chasing Fairness in Graphs: A GNN Architecture Perspective. Proceedings of the AAAI Conference on Artificial Intelligence, 38(19), 21214-21222. https://doi.org/10.1609/aaai.v38i19.30115
[2] Liu, X.; Jin, W.; Ma, Y.; Li, Y.; Liu, H.; Wang, Y.; Yan, M.; and Tang, J. 2021. Elastic graph neural networks. In International Conference on Machine Learning, 6837–6849. PMLR.
[3] Rockafellar, R. T. 2015. Convex analysis. Princeton university press.